



슬럼(Slurm) 작업 스케줄링 최적화
- NovaTier로 GPU 멀티테넌트와 무한 확장 구현

연구 조직이 커지고 GPU 학습이 일상화될수록, HPC 클러스터는 ‘좋은 장비를 많이 모아둔 곳’에서 ‘공유 자원을 운영하는 서비스’로 성격이 바뀝니다. 초반에는 몇 명이 순서대로 사용하면 됐지만, 팀이 늘고 프로젝트가 병렬로 굴러가기 시작하면 대기열이 곧 불만이 되고, 불만은 곧 운영 리스크가 됩니다. ‘왜 내 잡(job)은 이렇게 오래 기다리나’, ‘누가 GPU를 독점하나’, ‘짧은 디버깅 잡이 왜 대규모 학습 잡 때문에 계속 밀리나’ 같은 질문이 반복될 때, 운영팀은 큐를 수동으로 조정하는 데 시간을 쓰고 연구자는 실행을 기다리며 실험 리듬을 잃습니다. 이때 필요한 것은 단순 증설이 아니라 스케줄링 최적화이며, 그 최적화는 결국 표준화된 운영 기반 위에서만 지속적으로 성과를 냅니다.
이번 글은 Slurm Workload Manager를 HPC 스케줄링의 기본으로 삼고, GPU 영역은 NovaTier의 자체 스케줄링으로 확장성과 멀티테넌트를 강화하며, 외부적으로는 Kubernetes 및 타 스케줄러(LSF, PBS)와의 연동까지 고려하는 현대적 운영 모델을 ‘운영팀·연구자 관점’에서 이야기해 보고자 합니다. Slurm은 공식 문서에서 오픈소스 기반의 ‘내결함성(fault-tolerant), 고확장성(highly scalable)’ 클러스터 관리 및 잡 스케줄링 시스템으로 소개됩니다. 즉, 지금은 작게 시작하더라도 운영 원칙을 표준으로 고정해 두고, 확장 국면에서도 같은 방식으로 성장할 수 있는 기반이라는 뜻입니다.
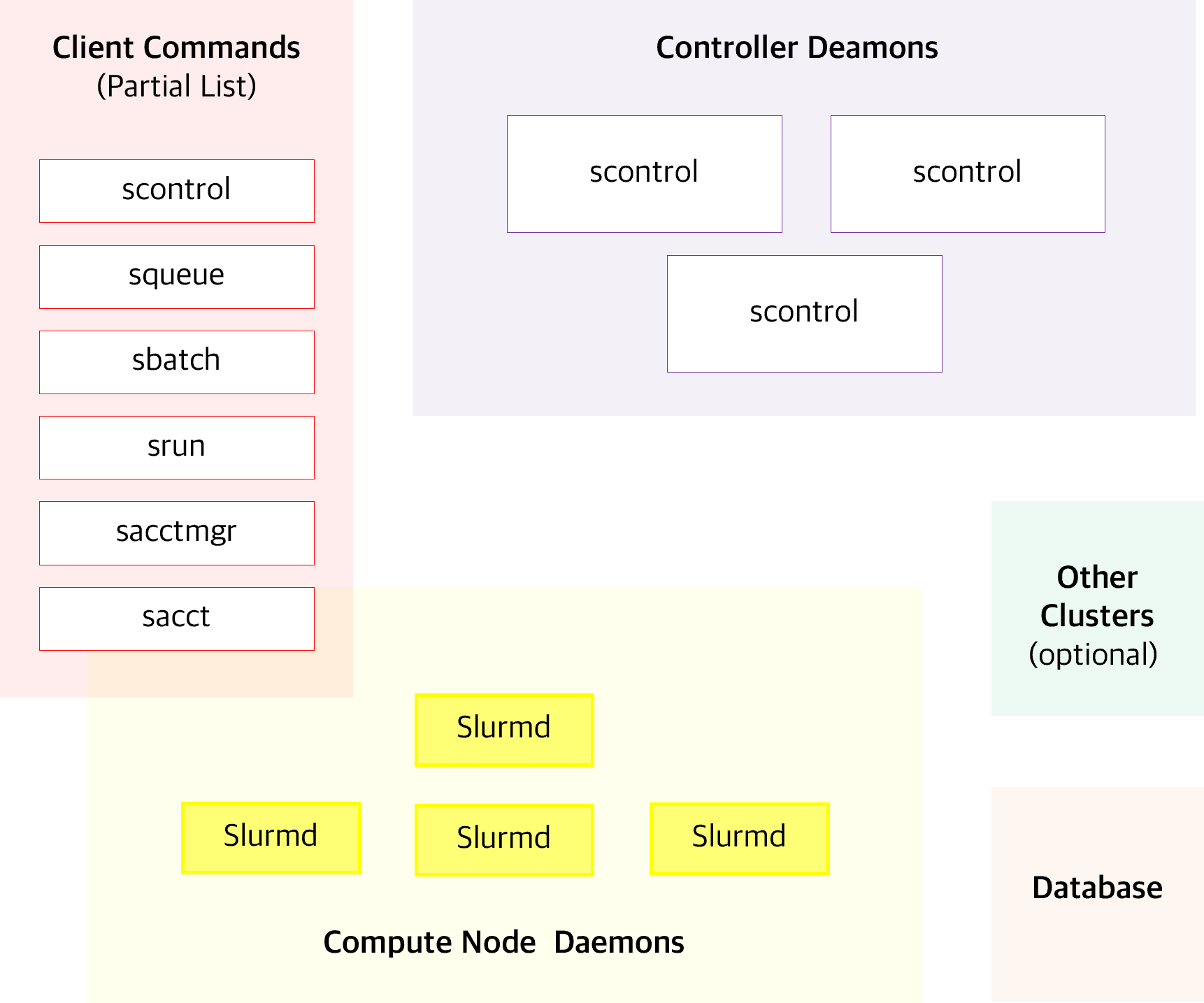
Slurm 구성과 흐름을 직관적으로 보여주는 공식 이미지





