


Product
슬럼(Slurm) 작업 스케줄링 최적화
- NovaTier로 GPU 멀티테넌트와 무한 확장 구현

연구 조직이 커지고 GPU 학습이 일상화될수록, HPC 클러스터는 ‘좋은 장비를 많이 모아둔 곳’에서 ‘공유 자원을 운영하는 서비스’로 성격이 바뀝니다. 초반에는 몇 명이 순서대로 사용하면 됐지만, 팀이 늘고 프로젝트가 병렬로 굴러가기 시작하면 대기열이 곧 불만이 되고, 불만은 곧 운영 리스크가 됩니다. ‘왜 내 잡(job)은 이렇게 오래 기다리나’, ‘누가 GPU를 독점하나’, ‘짧은 디버깅 잡이 왜 대규모 학습 잡 때문에 계속 밀리나’ 같은 질문이 반복될 때, 운영팀은 큐를 수동으로 조정하는 데 시간을 쓰고 연구자는 실행을 기다리며 실험 리듬을 잃습니다. 이때 필요한 것은 단순 증설이 아니라 스케줄링 최적화이며, 그 최적화는 결국 표준화된 운영 기반 위에서만 지속적으로 성과를 냅니다.
이번 글은 Slurm Workload Manager를 HPC 스케줄링의 기본으로 삼고, GPU 영역은 NovaTier의 자체 스케줄링으로 확장성과 멀티테넌트를 강화하며, 외부적으로는 Kubernetes 및 타 스케줄러(LSF, PBS)와의 연동까지 고려하는 현대적 운영 모델을 ‘운영팀·연구자 관점’에서 이야기해 보고자 합니다. Slurm은 공식 문서에서 오픈소스 기반의 ‘내결함성(fault-tolerant), 고확장성(highly scalable)’ 클러스터 관리 및 잡 스케줄링 시스템으로 소개됩니다. 즉, 지금은 작게 시작하더라도 운영 원칙을 표준으로 고정해 두고, 확장 국면에서도 같은 방식으로 성장할 수 있는 기반이라는 뜻입니다.
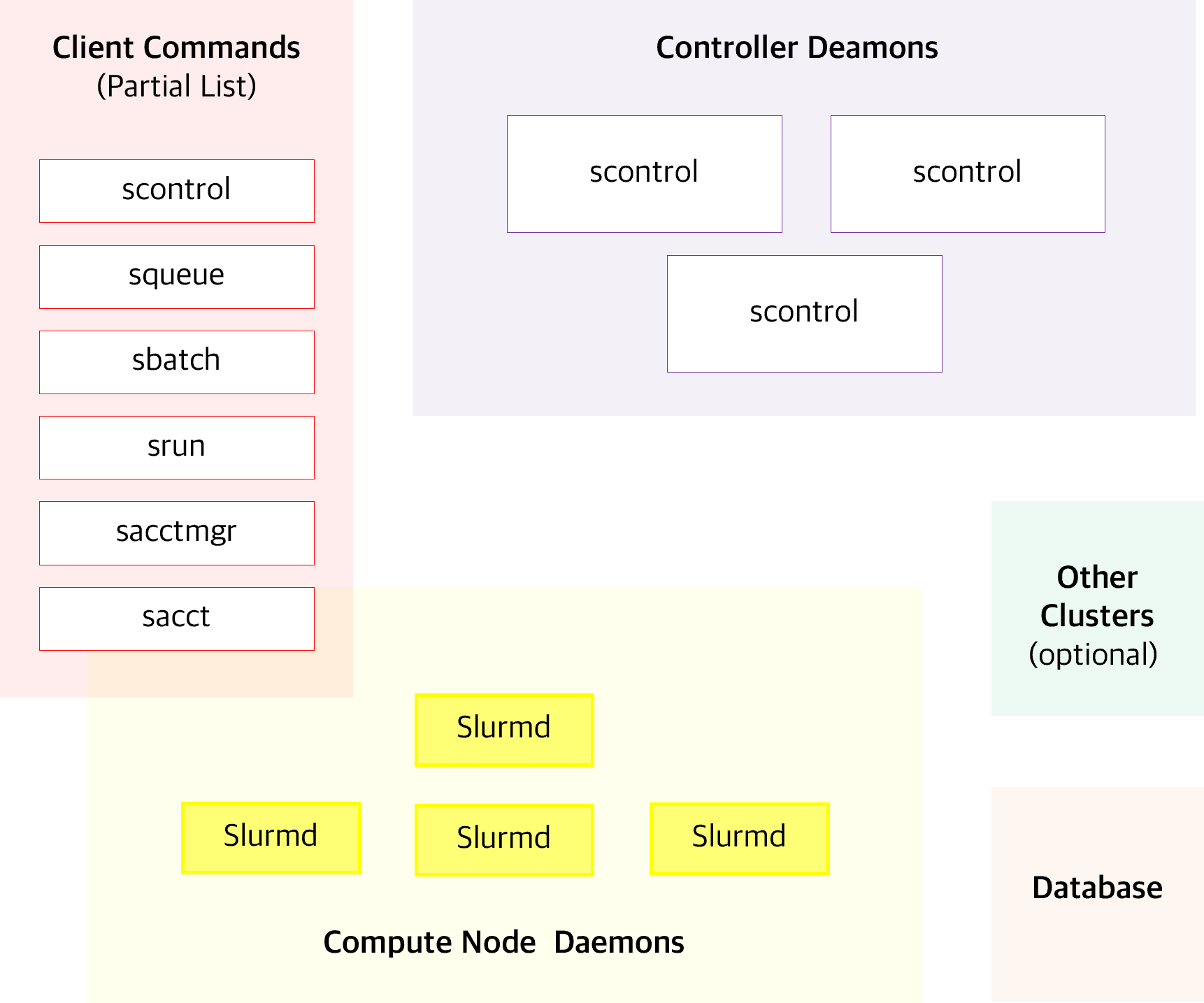
Slurm 구성과 흐름을 직관적으로 보여주는 공식 이미지
운영팀 관점: Slurm은 ‘사람이 하던 운영’을 ‘정책이 하는 운영’으로 바꾼다
운영팀이 진짜로 힘든 순간은 자원이 부족할 때가 아니라, 자원 배분 원칙이 흔들릴 때입니다. 특정 팀 잡만 유난히 빨리 도는 것처럼 보이거나, 긴 잡과 짧은 잡이 섞이면서 큐가 비정상적으로 길어지는 순간 운영은 곧 민원 대응이 됩니다. 이런 문제를 사람이 수동으로 조정하기 시작하면 운영 품질은 담당자의 경험에 종속되고, 인수인계·교대·확장 모두가 리스크로 변합니다.
Slurm의 가치는 이 불안정성을 ‘정책으로 고정’하는 데 있습니다. 파티션(Partition)과 우선순위, 계정/사용자 기반 정책을 통해 운영팀은 자원을 ‘그때그때’ 배분하는 대신 ‘원칙대로’ 배분하게 만들 수 있고, 운영 품질을 사람 대신 시스템이 유지하게 됩니다. Slurm이 ‘fault-tolerant, highly scalable’을 표방하는 이유도 결국 확장 국면에서 표준화가 안정성을 만든다는 실전 경험과 맞닿아 있습니다.
체감되는 최적화는 여기서 시작한다: Backfill이 유휴를 줄이고 처리량을 올린다
스케줄링 최적화에서 가장 빠르게 체감되는 변화는 ‘클러스터가 덜 논다’는 것입니다. Slurm의 대표 전략 중 하나인 ‘Backfill(백필)’은 큰 잡이 예약해 둔 실행 슬롯 사이의 빈 시간에 작은 잡을 끼워 넣어 유휴 시간을 줄이는 방식으로 설명됩니다.
운영팀 입장에서는 Backfill이 ‘자원 활용률을 올리는 메커니즘’이지만, 연구자 입장에서는 더 직관적인 의미가 있습니다. 디버깅, 짧은 전처리, 작은 파라미터 테스트 같은 작업이 계속 밀리면 실험 루프가 느려지고, 느려진 실험 루프는 곧 연구 속도를 떨어뜨립니다. Backfill이 안정적으로 적용된 환경에서는 이런 짧은 잡들이 ‘틈새 시간’을 활용해 더 자주 실행될 수 있어, 연구자의 반복 실험 주기가 단축됩니다. 결국 Backfill은 운영 KPI(활용률)와 연구 KPI(실험 회전율)를 동시에 개선하는 ‘첫 번째 최적화 레버’가 됩니다.
공정성은 분위기가 아니라 근거여야 한다: Fairshare는 신뢰를 만든다
클러스터가 공유 인프라로 운영되면 공정성은 기술 이슈이자 신뢰 이슈가 됩니다. 공정성의 기준이 불명확하면 운영팀은 매번 설명해야 하고, 연구자는 “내가 손해 본다”는 감정을 갖게 됩니다. Slurm은 이러한 문제를 줄이기 위해 Fairshare 개념을 제공하며, 그 중 Fair Tree 알고리즘은 사용자/계정의 우선순위를 산정하는 방식과 개념을 문서화합니다.
여기서 중요한 건 알고리즘 자체보다 “운영이 설명 가능해진다”는 점입니다. 공정성 모델이 합의되고 시스템에 반영되면, 운영팀은 예외처리보다 정책 튜닝에 집중할 수 있고, 연구자는 예측 가능한 대기 경험을 바탕으로 실험 계획을 세울 수 있습니다. Slurm은 이런 운영의 ‘설명 가능성’을 제공하는 표준 기반으로 작동합니다.
GPU 시대에도 Slurm이 중심인 이유: GPU만이 아니라 “자원 조합”을 할당한다
GPU 스케줄링을 자체적으로 고도화하는 조직이 늘어나는 것은 자연스러운 흐름입니다. GPU는 비싸고, 학습 잡은 길며, 멀티테넌트 환경에서는 파편화와 독점 문제가 빈번합니다. 그러나 현장에서 성능이 무너지는 원인은 종종 GPU가 아니라 CPU/메모리/노드 배치, 네트워크, 파일시스템 I/O 등 클러스터 레벨 자원 조합에서 발생합니다. 즉 GPU만 똑똑하게 스케줄링해도 전체 처리량이 오르지 않는 경우가 흔합니다.
Slurm은 이 복합성을 다루는 ‘기준점(single source of truth)’이 됩니다. Slurm은 GPU를 GRES(Generic Resource)로 정의해 잡 요청과 자원 할당에 포함시킬 수 있으며, NVIDIA MIG처럼 GPU를 분할해 운영하는 환경도 자원으로 취급할 수 있습니다. 이 모델이 제공하는 가치는 단순히 ‘GPU를 배정한다’가 아니라, GPU가 포함된 잡이 요구하는 전체 실행 조건을 운영 표준 위에서 정합성 있게 통제한다는 점입니다.
NovaTier가 만드는 GPU 차별화: ‘무한 확장’과 ‘멀티테넌트’를 운영 현실로
여기서 NovaTier의 가치가 선명해집니다. Slurm이 HPC 운영을 표준화해 CPU/메모리/노드와 잡 라이프사이클을 안정적으로 통제하는 동안, GPU 영역에서는 NovaTier의 자체 스케줄링이 확장 노드를 통해 사실상 무한정 확장 가능한 구조를 제공함으로써 수요 급증을 흡수합니다. 운영팀이 대기열 증가에 대응하는 방법이 ‘장비 구매’ 하나뿐이면, 수요가 급격하게 변할 때 운영은 늘 뒤처질 수밖에 없습니다. 확장 노드 기반 전략은 이 구조적 한계를 완화해, 운영팀이 ‘증설’ 외에도 대응 수단을 갖게 합니다.
또한 NovaTier의 멀티테넌트 지원은 GPU를 ‘공유 자원’으로 운영해야 하는 조직에 특히 중요합니다. 서로 다른 팀이 동시에 학습을 돌리고, 서로 다른 우선순위를 갖고, 서로 다른 실행 패턴을 보일 때 멀티테넌트는 단지 계정 분리 이상의 의미를 가집니다. 테넌트 단위로 정책과 격리를 설계할 수 있어야 공정성과 활용률을 함께 끌어올릴 수 있고, 그 위에서 연구자들은 “내 실험이 언제쯤 돌 수 있는지”를 더 예측 가능한 방식으로 받아들이게 됩니다. 이때 Slurm이 제공하는 표준 운영 기반은 GPU 최적화가 안정적으로 성과를 내도록 받쳐주는 ‘바닥’이 됩니다.
외부 연동이 곧 확장성이다: Kubernetes + LSF/PBS까지 ‘연결되는 스케줄링’
오늘날 연구 파이프라인은 점점 Kubernetes 기반 워크플로우, 사내 포털, 자동화 파이프라인과 결합됩니다. 동시에 기존 HPC 환경에서는 LSF나 PBS 같은 레거시 스케줄러가 이미 자리 잡고 있는 경우가 많아, 전환·공존·연동 시나리오가 현실적인 요구가 됩니다. 즉 ‘연동 가능’은 기능이 아니라, 조직이 기술 스택을 확장할 때 마찰을 줄여주는 전략입니다.
Slurm은 이를 위해 slurmrestd 기반 REST API를 제공하며, JSON Web Token 기반 인증을 포함한 REST API 구성과 목적을 문서로 제공합니다. 외부 시스템이 HTTP 기반으로 잡 제출/조회/관리 등을 수행할 수 있다는 것은, Kubernetes 기반 플랫폼과의 연결이나 포털/자동화 도구 연동에서 운영 부담을 줄이는 핵심 조건이 됩니다.
또한 멀티 클러스터 관점에서는 Slurm의 Federation(페더레이션) 기능이 여러 클러스터를 연합하고 피어-투-피어 방식으로 스케줄링을 확장할 수 있음을 명시합니다. 확장 노드 기반의 GPU 확장 전략과 결합할 경우, 운영 표준을 유지하면서도 인프라를 단계적으로 확장하는 장기 그림을 그릴 수 있습니다.
마무리: Slurm의 가치는 표준이고, NovaTier는 GPU 운영의 확장이다
정리하면, Slurm은 운영팀에게는 정책 기반 운영과 설명 가능한 공정성을, 연구자에게는 재현 가능한 실행과 실험 회전율 개선의 기반을 제공합니다. 그리고 GPU 시대의 차별화는 NovaTier가 담당합니다. 확장 노드 기반의 무한 확장과 멀티테넌트 지원은 GPU를 ‘서비스’로 운영하려는 조직이 반드시 풀어야 할 문제를 해결하는 방향이며, Slurm의 표준 운영 기반 위에서 그 효과는 더 안정적으로 구현됩니다. 마지막으로 Kubernetes 및 LSF/PBS 연동 가능성은 조직의 워크로드가 어디로 확장되든 스케줄링 체계가 고립되지 않게 만드는 보험이 됩니다.



















